As we’ve previously described on this blog, we had severe performance issues in the e-conomic application during August. Below we’ll try to go into more detail about exactly what happened and why, and also look at what steps we’re taking to prevent something like this from happening again.
Firefighting
From an operational perspective, what we experienced in August was near-constant fighting of fires caused by a number of different factors (with session locks as the main culprit), all resulting in poor performance and slowdowns in the e-conomic application.
These were the underlying issues that occurred during August:
Database CPU load. Our performance issues started on August 10 when we saw a heavy load on our main database that caused slowdowns in the application. This turned out to be caused by code changes introduced during July which had so far gone unnoticed due to low summer activity. With users back from vacation, the issue now started to have a serious performance impact.
We took various steps to identify and fix this issue. On August 11 we performed a failover to our backup database server to see if the issue was due to an error on the main database. This failover took 30 seconds and threw users off the system.
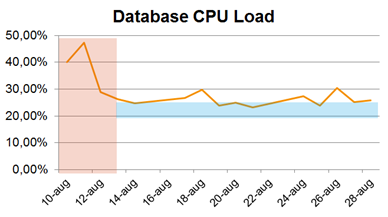 The next day, August 12, we managed to locate the faulty code and implement a fix that solved the CPU issue.
The next day, August 12, we managed to locate the faulty code and implement a fix that solved the CPU issue.
The CPU load has been under control since then but we are still monitoring and locating candidates for optimizations.
In terms of learnings, this issue has made it clear that we need to take action on indicators as they move in the wrong direction, even if they don’t cross any critical thresholds. That way we can react to something like an increase to the CPU load, regardless of whether it actually crosses any alert levels.
Session state locks. This was the main issue affecting performance during August. For the basic details on how session state and locks work, see the performance update from September 1.
The performance issues arising from session state locks were a constant issue from the second half of August 20 and all the way up to the Danish VAT reporting deadline on September 1, a period with very high user activity and high numbers of simultaneous users on the system.
The typical pattern during this period was that as more and more users started using the system during the morning, the session state database was unable to keep up and started queueing requests, leading to rapid increases in response times. This lasted until we removed the locks on the session state database and reset the servers, which caused a gradual return to normal. These slowdowns would then recur at various intervals all through peak hours.
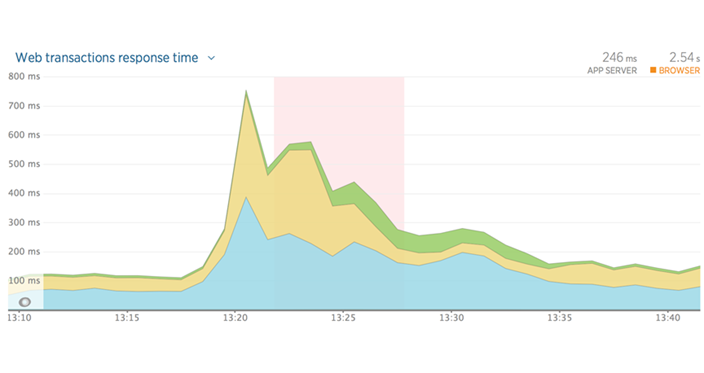
As detailed previously, we’re working on removing the session state locks from the system, starting with the most affected parts of the application, e.g. the document handling functionality.
To remove locks from the system generally, we need to look into how session data is used in different parts of the code to ensure that removing locks won’t affect any parts of the application negatively. In a number of places we will need to rewrite the code so that locks are not required to perform multiple actions simultaneously (e.g., sending and receiving data).
By the way, note that when we talk about removing locks, this only means unlocking session data, i.e., data used to identify the user to servers and other parts of the system – not actual bookkeeping data. This data is handled the same way as always.
Finally, we will upgrade the session state database to a faster version that doesn’t lock the rows containing each user’s session data. To do this, and also update SQL Server on the main database, we will shut down the application on September 26, 6 PM until September 27, 6 AM.
Hosting provider and external services. Proving that when it rains it pours, we also experienced connectivity issues in August caused by network issues on part of our hosting provider and a number of external services failing.
On August 27, network issues caused all servers to be temporarily unavailable, with blogs, websites and the application all down.
We run a number of non-essential external services in the Amazon Cloud. Later on August 27, these external services became unresponsive through an error on our part. Normally, external services not responding should not affect application performance, but only disable certain parts of the application. But in this case it did, leading to a temporary slowdown until we removed the dependency on this service.
The learning from this issue is of course to ensure that the status of external services doesn’t impact on the general performance.
Next steps
Our next milestone is the Danish VAT deadline in November when we will again see increased numbers of users on the system. From now and until November, all available resources and personnel will be at work to ensure we maintain a high performance during this period.
The upgraded session state database that we will introduce during the service window on September 26-27 should provide a big step in the right direction of improved performance during high loads. But we have also started a number of other initiatives to help prevent a situation like in August from arising again.
In essence, we’re looking at all parts of our setup to see if we can make improvements that will help increase stability and performance. This includes network, hardware, database, operating systems, deployment setup, external services – down to specific parts of the code.
In the short and medium term, i.e. until next VAT deadline, we’re mainly looking to:
- Upgrade our operating system
- Improve session state handling (including removing locks)
- Ensure independence from external services
- Optimize specific parts of the code
- Improve handling of spinners and server errors
In terms of the last item, one recurring issue is that we sometimes have users telling us they see loading spinners when working in e-conomic, even though all our monitoring results indicate that the system is running smoothly.
We believe this is caused by the browser sometimes failing to correctly process the response from the server, even when that response succeeds. This will then give the impression of performance issues for the specific user.
As a first step towards solving this, we are working on improving logging and monitoring to get a better overview of which parts of the application and which customers are affected. We should then be able to start implementing improvements for handling server responses in different scenarios.
Plans further ahead
Looking beyond the November VAT deadline, we will keep on looking at the various parts of our setup to locate areas for improvement.
Specifically, we plan to move to a different type of infrastructure that will allow for increased resilience, and we want to make changes to our architecture so that we can make different functionality and customers more independent from each other in terms of performance.
To sum up, we will continue to stay highly focused on performance and stability in both the short term and the long term.