

Læs artiklen på dansk
e-conomic has experienced a series of outages starting on the 5th of February and this is the first post trying to shed a light on what is happening and what we are doing to address those outages as fast as possible.
First, let’s give you an overview of what we’re doing to get back to a stable place. You will find more detailed information after the incident descriptions, because there might be some background information needed.
What we’re doing to address this issue
We have established a cross-department task force that can act quickly and pull in any required personnel needed, so we can give those issues our full attention and provide stability as soon as possible.
Despite the issues, customer data has not been affected in any way. There was no impact on security or privacy.
In parallel we’ve stopped the modernization of our endpoints until e-conomic is fully stable again and we can be certain that no issues are created.
5th of February – duration roughly 2 hours
This was a single outage related to a misconfiguration of our translation service while migrating to a new Continuous Deployment tooling. When it became clear a service dependency was failing, the issue was resolved with a re-deployment of the translation services, followed by a redeployment of e-conomic.
To avoid any issues like this moving forward, we have increased the observability, enhanced our review of code and configuration changes of the translation service and will be monitoring its health a lot more aggressively.
8th February and onwards – increased system instability
The incident on the 8th of February kicks off a series of incidents that highlight some misconfigurations that have caused us a great amount of trouble as we are modernizing our software and the platform it runs on.
8th of February – 55 minutes
14th of February – 3.5 hours
16th of February – 50 minutes
In order to explain the outages on the 8th and 14th, we need to provide some technical background first.
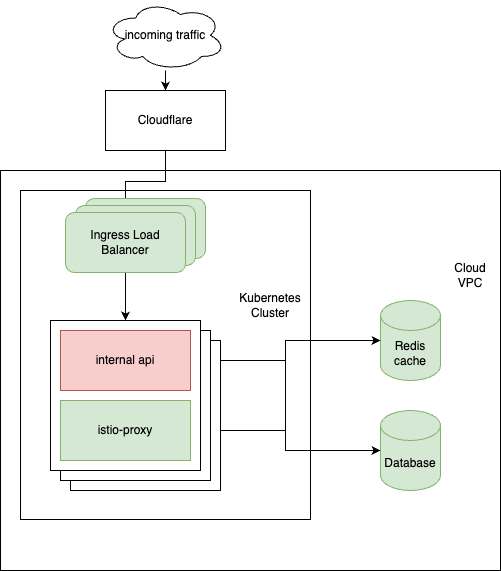
We are using a service mesh called Istio on our Kubernetes clusters, which provides security, traffic management and observability features for us. To explain this, here is a very simplified overview of this specific area’s network topology.
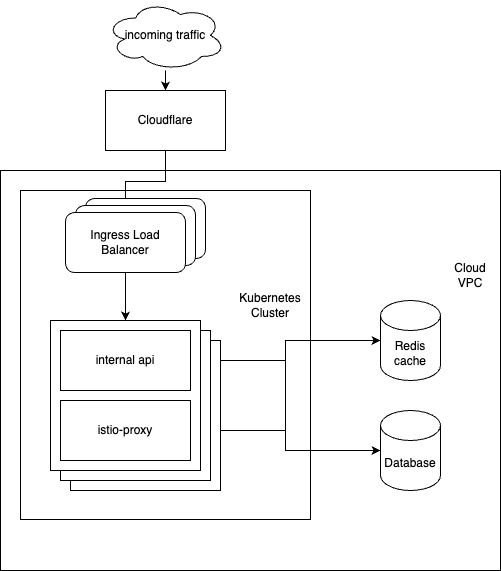
On February the 8th we noticed issues on the Istio ingress as well as our internal-api containers. After a deployment, the containers became stuck in a restart loop, making them unable to serve external traffic.
After adjusting the resources allotted to the Istio ingress and redeploying the application, the problem subsided. During this period we saw a lot of different errors, and it was challenging to determine where the fault originated.
Aside from the immediate actions to make the Ingress more robust, we also spent some time upgrading our observability to get more information about our service mesh and send automated alerts should this happen again.
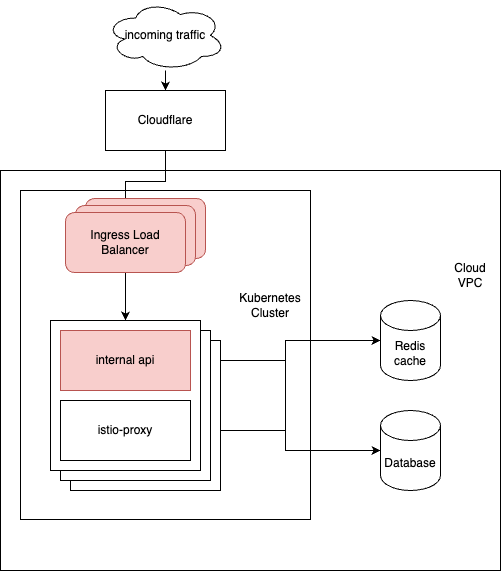
On February the 14th we saw a similar problem arise, but this time the Ingress coped with the additional resource need and we only saw the internal-api containers restart. We also noticed that our database had a lot of blocking operations in a table that serves the internal api. This table is a fallback for our Redis cache (making sure your sessions stay preserved between the individual containers), so we turned the database fallback off. This provided some improvement, but while the application was in a slightly better (albeit very poorly performing) state, we noticed that a lot of connections didn’t reach the cache anymore.
After some investigation and clearing the cache we pivoted to consider the SQL fallback as working, cutting out Redis and the system became available.
During the root cause analysis we detected a misconfiguration of the Istio proxy sidecar, and we made configuration changes to ensure it is more robust and supports growing traffic. After this upgrade, we were able to bring the Redis connections online again and have not detected any further issues on those.
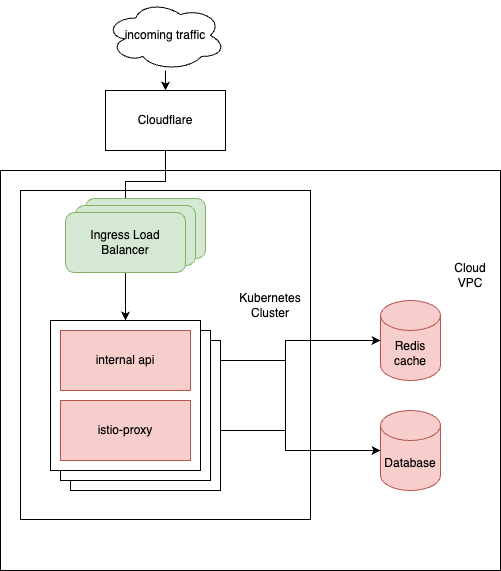
On February the 16th we saw internal-api pods restarting again; however, the culprit seemed to lie with a series of blocking processes on the Database.
Our modernization efforts required us to store our users’ SessionState in a common location for all our containers to access. The implementation of how to update this database table was problematic and unnecessarily blocked our Database. We found a remedy for the immediate effects quickly (to bring the system up again) and made sure that this particular blocking doesn’t occur anymore in the future by first disabling the Database fallback, and over a bit more time restructuring the way this particular table is being accessed.
As further action we have provided our internal-api with its own node pool, to increase and better control the resources it has available.
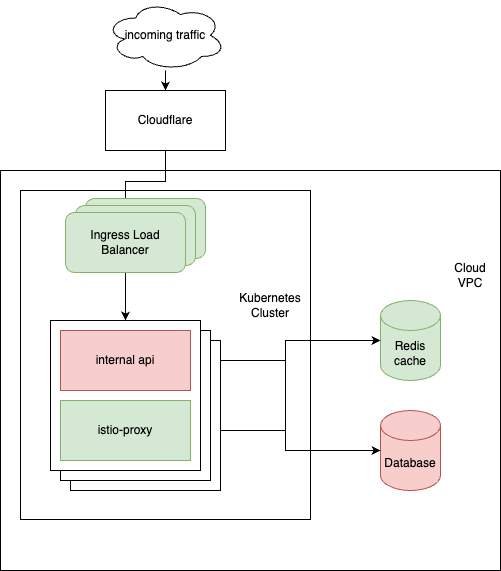
February 19th – investigations ongoing
On the 19th of February we experienced two (much shorter) downtimes. Thankfully we could bring the system up in 10 and 3 minutes respectively, a result of our increased observability and incident management procedures which we keep improving.
We are still in the midst of analyzing the root cause, but preliminary results show that this issue was caused by excessive memory consumption in the internal-api. To debug this further we have attached a profiler to allow us to see what is consuming this much memory and make sure we handle any further incidents more gracefully.
What we have done so far to mitigate the issues
- Provide additional observability to the container resources
- Provide alerts for fast detection of any issues like those
- Create runbooks for this issue to get our MTTR (mean-time-to-restore) to under 10 minutes
- Configure all our containers to have sufficient resources
- Internal-api got its own node-pool to make sure there is no impact on its resources from other parts f the system
- Optimize our service mesh configuration
- Improve database procedures for SessionStates specifically
- Isolate endpoints that might be causing issues into separate instances, for improved debugging and to minimize impact
- Continuous monitoring of resource configurations (setup done, monitoring ongoing)
Next steps
- Investigate if we can improve our connections to Redis (mid-term)
- Redesign database connection pooling for robustness (long term)
- Work on improved startup probes
- Improve database setup to allow more connections at the same time
Read the post in Danish below.
Udfald på e-conomic applikationen
e-conomic har oplevet en række udfald, der begyndte 5. februar. Dette er det første indlæg, som forsøger at belyse, hvad der sker, og hvad vi gør for hurtigst muligt at tage hånd om disse udfald.
Først vil vi give dig et overblik over, hvad vi gør for at komme tilbage til stabil drift. Du kan finde mere detaljeret information efter beskrivelserne af de enkelte hændelser, da der kan være behov for baggrundsinformation.
Hvad gør vi ved problemerne?
Vi har nedsat en taskforce på tværs af afdelinger, som kan handle hurtigt og tage fat i de nødvendige personer for at give problemerne fuldt fokus og sikre stabil drift så hurtigt som muligt.
Kundedata er på ingen måde påvirket af problemerne. Der har heller ikke været indvirkning på sikkerheden eller beskyttelsen af persondata.
Vi stopper samtidig moderniseringen af vores endpoints, indtil e-conomic kører helt stabilt, og vi kan være sikre på, at der ikke opstår problemer.
5. februar 2024 – cirka to timers varighed
Dette var et enkelt udfald relateret til en fejlkonfiguration af vores oversættelsesapplikation i forbindelse med migrering til et nyt værktøj til Continuous Deployment. Da vi blev klar over fejlen, løste vi problemet med en genstart af oversættelsestjenesten efterfulgt af en genstart af e-conomic.
For at undgå lignende problemer fremover har vi øget overvågningen og forbedret vores gennemgang af kode og konfigurationsændringer i oversættelsesapplikationen – og vil holde meget mere øje.
8. februar og fremefter – øget ustabilitet i systemet
Hændelsen 8. februar markerer begyndelsen på en række hændelser, som har kastet lys over nogle fejlkonfigurationer, som har skabt udfordringer i moderniseringen af vores software og den platform, softwaren kører på.
8. februar: 55 minutter
14. februar: 3,5 timer
16. februar: 50 minutter
Det kræver noget teknisk baggrundsinformation at forklare udfaldene den 8. og 14. februar:
Vi bruger et service mesh kaldet Istio på vores Kubernetes-cluster, som giver os funktioner til sikkerhed, trafikstyring og observerbarhed. Til forklaring af dette ses her et meget forenklet overblik over dette specifikke områdes netværkstopologi:
8. februar bemærkede vi problemer med indgående netværkstrafik og med vores interne API-containere. Efter en implementering sad containerne fast i en genstartsløkke, som gjorde dem ude af stand til at betjene trafik udefra.
Efter at vi havde justeret de tildelte ressourcer til Istio og genstartet applikationen, aftog problemet. I dette tidsrum så vi mange forskellige fejl, og det var svært at se, hvor fejlene opstod.
Ud over det, vi umiddelbart kunne gøre for at gøre Istio mere robust, brugte vi også tid på at opgradere vores overvågning, så vi kunne få mere information om vores service mesh og sende automatiske alarmer, hvis der igen opstod problemer.
14. februar oplevede vi et lignende problem, men denne gang håndterede Istio det ekstra behov for ressourcer, og vi så kun, at de interne API-containere genstartede. Vi lagde også mærke til, at vores database havde mange blokerende operationer i en tabel, der betjener vores interne API. Tabellen er fallback for vores Redis cache (som sikrer, at sessioner bevares mellem de enkelte containere), så vi slukkede for databasen som fallback. Det medførte en vis forbedring, men mens applikationen var i en lidt bedre tilstand (om end med dårligere performance), kunne vi se, at mange forbindelser ikke længere nåede cachen.
Efter nogle undersøgelser og en rydning af cachen tydede alle vores analyser på, at SQL-fallbacket fungerede som forventet. Vi stoppede brugen af Redis, og systemet blev tilgængeligt.
Under root cause analysis opdagede vi en fejlkonfiguration af Istio, og vi foretog konfigurationsændringer for at sikre, at den er mere robust og understøtter voksende trafik. Efter denne opgradering kunne vi bringe Redis-forbindelserne online igen, og vi har ikke registreret yderligere problemer med dem.
16. februar oplevede vi igen, at interne API-pods genstartede. Her pegede vores analyse og overvågning på blokerende processer i vores database.
Modernisering kræver, at vi gemmer brugernes sessionstilstand på en fælles location, som alle vores containere kan tilgå. Implementeringen af, hvordan denne database-tabel skal opdateres, var problematisk og blokerede vores database unødigt. Vi fandt hurtigt en løsning på de umiddelbare virkninger (at få systemet op at køre igen) og sikrede os, at denne blokering ikke opstår i fremtiden ved først at deaktivere database fallbacken – og over tid omstrukturere måden, denne specifikke tabel tilgås på. Vi har desuden forsynet vores interne API med en egen node-pool for at øge og forbedre kontrollen med de ressourcer, den har til rådighed.
19. februar – undersøgelser i gang
Den 19. februar oplevede vi to udfald (af meget kortere varighed). Heldigvis kunne vi genoprette systemet på henholdsvis 10 og 3 minutter: Et resultat af vores øgede overvågning og procedurer for håndtering af hændelser, som vi fortsat forbedrer.
Vi er stadig i fuld gang med at analysere årsagen, men de foreløbige resultater viser, at dette problem skyldes et unormalt højt hukommelsesforbrug i den interne API. Vi har tilknyttet en profiler for at fejlfinde yderligere og se, hvad der bruger så meget hukommelse – og sikre os, at vi håndterer eventuelle fremtidige hændelser mere smidigt.
Her er et overblik over, hvad vi allerede har gjort, og hvordan vi fremadrettet vil arbejde med problemerne:
- Sikre yderligere overvågning af hardware-ressourcer
- Sørge for alarmer, så vi hurtigt opdager eventuelle problemer som disse
- Oprette runbooks for disse problemer, så vi kan sikre en MTTR (middeltid til genoprettelse) på under 10 minutter.
- Konfigurere alle vores containere, så de har tilstrækkelige ressourcer
- Det interne API har fået sin egen node-pool for at sikre, at dens ressourcer ikke påvirkes af andre dele af systemet
- Optimere konfigurationen af vores service mesh
- Forbedre database procedurerne for bruger sessioner specifikt
- Isolere endpoints, som muligvis forårsager problemer, i separate instanser for at forbedre fejlfinding og minimere indvirkning
- Undersøge, om vi kan forbedre vores forbindelse til Redis (midt-langsigtet)
- Omstrukturere vores database-forbindelser for øget robusthed (langsigtet)
- Arbejde på forbedrede opstarts-prober
- Forbedre database-opsætningen for at muliggøre flere forbindelser samtidig
- Løbende overvågning af ressource konfigurationer (opsætning udført, overvågning pågår)