

In the first quarter of 2024, e-conomic has experienced a series of connected outages that hit the core of our application. We have provided an update on what was going on during the incidents but would like to summarise the incident period and detail what actions have been taken to make sure this will not happen again.
Incident overview
The problems we experienced ranged from the 8th of February to the 13th of March. It spans a series of incidents, some that took multiple hours, others taking only a few minutes. In the scope of the incidents we have always worked hard to isolate and and improve our system, so the later incidents in March were considerably shorter than those in February.
8th to 16th of February – Session State problems
We are currently undergoing some technical modernization to move from Virtual Machines to Containers on some of our core components. This means that a series of requests from a customer could be answered by a VM or by a container at any point in time. In order to make sure that the customer experience is seamless, the Session State needs to be preserved in a “shared” location.
This location is a Redis cache that we’re hosting in Google Cloud with a fallback in our main SQL Database (in case Redis is non-responsive).
Below, you can see a simplified overview of the component architecture at the start of February.
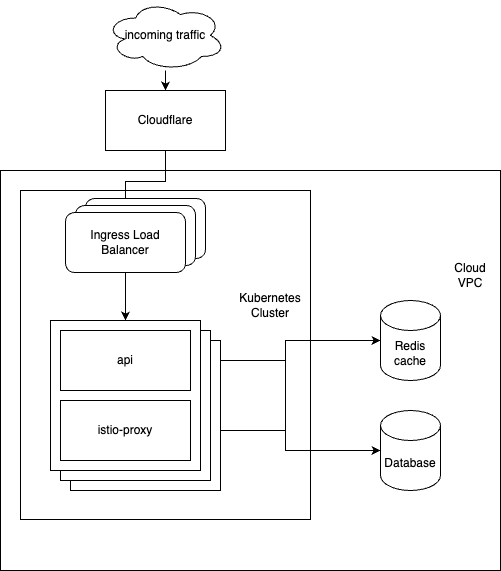
During the initial incidents, we observed issues on all of those components with the main issue originating out of the api. During high activity on our side (usually an ongoing feature deployment coinciding with high customer usage and some specific database functions being run) the different api instances could block each other from accessing the database. This led to them restarting and flooding the database even more. This particular issue with the Session State was resolved, both on Redis and on the Database side. You can read more details in our first writeup on the Tech Blog.
19th February to 13th of March – the journey to resilience
With the Session State problems out of the way, we still encountered issues with the api component. The overarching issues we have encountered are the following:
- Connection handling to other components (too many connections due to poor connection reuse)
- Sizing and scaling challenges due to undetected correlations between memory and CPU of the code migrated from VMs
- Incorrect handling of bulk operations
- Circular dependencies between api and other components
- Unclear ownership of components
At this point in time, we already had a task force up and running and working on any issues that were identified with a clear focus to not have this happen again and make the system more resilient. We found out that, due to the way some of the legacy code was structured, it could happen that a single endpoint could bring down the whole system if called often enough.
Splitting the API
The api consists of various different endpoints that were all running on multiple replicas of the same system. If a specific endpoint was being used a lot and had issues, it would bring a pod down, cascading to all the pods of this component eventually and creating a full outage.
The first step to deal with this was increased observability and making sure the people on duty were immediately informed about a pod going down. With this we could trigger actions the moment the issue occurred and this helped us greatly with identifying the root cause for the individual outage.
The main course of action however informed our new strategy for any further migration from VM to container: Different kubernetes deployments for different purposes. We started to do this simply to identify which endpoint was causing us trouble but ended up splitting the api into kubernetes deployments that group endpoints per business domain. This allows it to contain an outage to a specific business domain. During March, this happened a few times, where e-conomic generally was up, but a specific functionality was failing (Example of an overnight outage of SmartBank – the rest of the application was available).
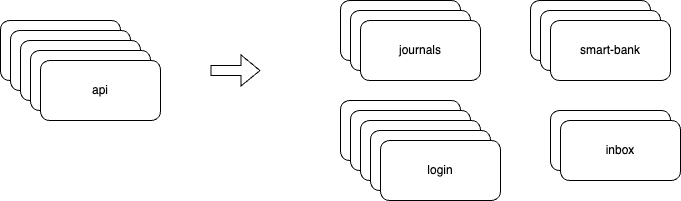
The above is an example of the splits we have made for illustration purposes. This gives us more flexibility, and provides the following advantages:
- Better automatic scaling – more resources for endpoints that see heavy traffic, less for those that don’t
- More resources permanently for heavy endpoints that need (for example) more memory than others
- Circular dependencies are split between different kubernetes deployments
- Heavy endpoints interacting with external systems are isolated and can scale up as needed.
Code improvements
In the months since February we have worked diligently on improving the underlying codebase and anything that could cause those problems or general slowdowns in the area. Improvements were made among others in the following areas:
- Improvements to Http connection handling for communication with external components
- Optimization of communication with our Redis Cache
- Optimizations around thread contention
- Optimizations on our Session State table in SQL
- Improvements on bigger operations in the Journals area
- Improvements for memory usage within Journals and Pdf Generation
This is, of course, just a quick glance at the main points we were investigating in the code base and many other investigations took place across all our teams to improve and make the code base more resilient.
Overall improvements
- Incident handling and communication
– Communicating clearly on the status page with emphasis on providing relevant information without overloading on updates moving forward - Observability – special focus on:
– Horizontal Pod Autoscaler and being able to scale when needed
– Deployment setup to be without downtime
– Virtual Pod Autoscaler to provide validation and recommendations for pod resource usage
– Instant notification in case any of our kubernetes deployments go down
– Elaborate dashboards to get an overview of our .net containerized services - Profiling memory issues while they are happening
- Improved best practices and requirements for our container setup for high availability of our services and memory optimization
- Rollout of our new CD system to the e-conomic components to be able to provide improvements within a few minutes rather than hours (this was already ongoing but fast-tracked due to the incident)
- Review of our Redis connection and our service mesh by an independent consultant to make sure its up to standard and we’re not missing any potential improvements
- Optimizations on our service mesh, kubernetes node pools and overall setup of our infrastructure to reduce the chance of full outages
- Improvements for memory usage within Journals and Pdf Generation
Overblik over hændelser i Februar/marts
I første kvartal, oplevede e-conomic en række nedbrud som gav en række udfald i vores applikation. Vi har tidligere udsendt en opdatering om hvad der skete under hændelserne, men, for gennemsigtighedens skyld, vil vi her gerne opsummere selve hændelsesperioden, samt de foranstaltninger vi har nu taget for at sikre, at det ikke sker igen.
Hændelsesoversigt
Udfordringerne fandt sted fra den 8. februar til den 13. marts. I perioden skete der en række hændelser af vekslende varighed, nogle varede flere timer, andre kun få minutter. I forbindelse med hver hændelse, har vi arbejdet hårdt på at isolere de påvirkede dele og samtidig forbedre vores system. Dette bevirkede, at de senere hændelser i marts, var betydeligt kortere end de hændelser der fandt sted i februar.
8. til 16. februar – Session State problemer
I e-conomic arbejder vi hele tiden på at have en moderne og velfungerende platform. I den forbindelse er vi ved at foretage nogle tekniske opdateringer hvor vi flytter nogle dele af systemet fra virtuelle maskiner til en nyere virtualiseringsteknologi – “containers”, hvor flere containers deler et styresystem, i stedet for de virtuelle maskiner der hver har deres eget styresystem og fuld hardware-emulering. Derved bliver det i fremtiden meget nemmere og hurtigere at skalere ressourcer efter behov og på den måde give jer en mere stabil og hurtig oplevelse af e-conomic applikationen og vores API’er. Da vi ikke kan flytte hele systemet på én gang, har vi været nødt til at sikre at session-state data, altså den midlertidige information om brugeren der er logget ind og hvad de er i gang med på systemet, kunne deles på tværs af virtuelle maskiner og containere. Dette mellemlager er en “Redis cache” som vi har hostet på Google Cloud, foruden en nødplan hvor vi også gemmer session-data i vores primære SQL database (I tilfældet af at Redis ikke svarer).
Nedenfor kan du se et forenklet overblik over komponent-arkitekturen i starten af februar:
I uge 6 og 7 arbejdede vi netop på at flytte nogle dele fra virtuelle maskiner til containere på nogle af vores kernekomponenter. I løbet af hændelsen observerede vi nogle pludseligt opståede udfordringer på alle disse komponenter hvor hovedproblemet havde sin oprindelse i API’erne. Under meget høj aktivitet begyndte de forskellige API-instanser pludselig at blokere hinanden fra at få adgang til databasen. Som følge af dette, troede de enkelte API-instanser at de havde en fejl, hvorpå de er indstillet til at genstarte sig selv for at komme online igen.
Disse genstarter belastede dog blot databasen endnu mere.
(Høj aktivitet ser vi ofte ved en spidsbelastning fra partnere der bruger vores API’er eller en igangværende udrulning af funktioner samtidig med at mange kunder er online, samt ved nogle specifikke databasefunktioner).
Problemet vi beskriver her omkring session-state data blev løst i både på Redis og på databasen og du kan læse flere detaljer i vores første indlæg på Tech Blog.
19. februar til 13. marts – rejsen mod modstandsdygtighed
Med session-state udfordringerne løst, stødte vi stadig på problemer med API-komponenterne. De overordnede problemer vi oplevede var følgende:
- Håndtering af forbindelser til andre komponenter (for mange åbne forbindelser pga. dårlig genbrug af forbindelser).
- Udfordringer med ressourceallokering og skalering pga. uopdagede sammenhænge mellem hukommelse og CPU i den kode, der blev migreret fra virtuelle maskiner.
- Forkert håndtering af større masse-operationer.
- Cykliske afhængigheder mellem API og andre komponenter.
- Uklart internt ejerskab af komponenter.
På det pågældende tidspunkt havde vi allerede en dedikeret arbejdsgruppe, der arbejdede på at løse alle de problemer vi identificerede. De havde fokus på at forhindre at problemerne opstod igen, samt at gøre systemet mere robust. Her fandt vi ud af, at strukturen i dele af den gamle kode gjorde, at et enkelt endpoint (den specifikke funktion der bliver kaldt) kunne lukke hele systemet ned, hvis det blev kaldt rigtig mange gange i træk.
Opdeling af API’et
API’et består af forskellige endpoints, som alle kører på flere replikaer af det samme system. Hvis et specifikt endpoint blev brugt rigtig meget og havde problemer, ville det lukke en pod (en enkelt container) ned, hvilket ville sprede sig til de andre pods i komponenten og til sidst føre til en fuldstændig nedlukning af komponenten.
Det første skridt mod at håndtere dette var øget observerbarhed, samt at sikre, at de ansvarlige folk straks blev informeret, når en pod lukkede ned. Det betød, at vi kunne reagere så snart problemet opstod, og nemmere identificere årsagen til den enkelte hændelse.
Den vigtigste foranstaltning var dog en ny strategi for enhver yderligere migrering fra virtuelle maskiner til containers: Forskellige Kubernetes-udrulninger til forskellige formål. Dette startede vi med at gøre, for bedre at kunne identificere hvilket endpoint der skabte problemer. Men vi endte med at opdele API’et i Kubernetes-udrulninger, der grupperer endpoints I de respektive forretningsdomæner (funktioner i e-conomic såsom fx. kassekladde eller kontoplan). Det gjorde det muligt at begrænse en nedlukning til et specifikt forretningsdomæne, i stedet for at hele applikationen blev påvirket.
I marts skete det nogle enkelte gange, at en specifik funktionalitet fejlede (fx en nedlukning af Smart Bank om natten, hvor resten af applikationen var tilgængelig), men hvor e-conomic applikationen som helhed fungerede fint.
Eksemplet ovenfor illustrerer de opdelinger, vi har lavet. Disse giver os en del mere fleksibilitet og samtidig også følgende fordele:
- Bedre automatisk skalering – flere ressourcer til endpoints med høj trafik, færre til dem uden.
- Flere ressourcer allokeret permanent til de tunge endpoints, der f.eks. har brug for mere hukommelse end andre.
- Cirkulære afhængigheder er opdelt mellem forskellige Kubernetes-udrulninger
- Tunge endpoints, der interagerer med eksterne systemer, er isoleret og kan skaleres op efter behov.
Forbedringer af koden
I månederne siden februar har vi arbejdet hårdt på at forbedre den kode der ligger til grund for dette, samt alt det der kunne forårsage ovenstående problemer eller generelle slowdowns.
Vi har bl.a. forbedret følgende områder:
- Forbedringer af håndteringen af HTTP-forbindelser til kommunikation med eksterne komponenter
- Optimering af kommunikation med vores Redis-cache
- Optimeringer vedrørende delte ressourcer blandt tråde (instrukser)
- Optimeringer på vores session state-tabel i SQL
- Forbedringer af større operationer i forretningsdomænet kassekladder
- Forbedringer af hukommelsesforbrug i kassekladder og PDF-generering.
Dette er naturligvis kun et hurtigt overblik over de vigtigste ting, vi har undersøgt i kodebasen. Mange andre undersøgelser har fundet sted på tværs af alle vores teams for at forbedre kodebasen og gøre den mere robust.
Generelle forbedringer
- Håndtering af kommunikation ved hændelser:
– Kommunikere klart på statussiden med vægt på kun at give relevant information, uden for mange løbende opdateringer. - Synlighed – specielt med fokus på:
– Horizontal Pod Autoscaler og evnen til at skalere, når det er nødvendigt
– Udrulninger uden nedetid
– Automatisk justering af horisontal skalering af pods for at kunne få bedre validering og anbefalinger i forhold til ressourcebrug til pods.
– Øjeblikkelig notifikation, hvis nogen af vores Kubernetes-udrulninger går ned
– Udførlige dashboards for at få et overblik over vores .net-containeriserede tjenester - Mulighed for analyse af hukommelsesproblemer, mens de opstår
- Forbedrer best practice og krav til vores container-opsætning for høj tilgængelighed af vores tjenester samt optimering af hukommelse
- Udrulning af vores nye CD-system til e-conomic-komponenterne for at kunne levere forbedringer inden for få minutter fremfor timer (dette var allerede i gang, men blev fremskyndet på grund af de nævnte hændelser)
- Gennemgang af vores Redis-forbindelse og vores service mesh af en uafhængig konsulent for at kvalitetssikre og undgå at vi går glip af potentielle forbedringer
- Optimeringer af vores service mesh, Kubernetes-nodepuljer og den samlede opsætning af vores infrastruktur for at reducere risikoen for nedbrud.
- Forbedringer af hukommelsesforbrug i kassekladder og PDF-generering.